先说一个非常重要的参考资料,也就是 ftrace 作者本人的 pdf:ftrace kernel hook
接下来,主要跟着作者的思路,融入自己的一些思考,给大家解读一下 ftrace 究竟做了什么?
1. 什么是 ftrace ftrace,顾名思义,就是 function trace,针对函数级别的追踪调试机制。
我们平时是如何使用这个强大功能的呢?
1.1 如何使用 ftrace 可以通过 tracefs 和内核进行交互 ,比如向 current_tracer 文件中写入 function,内核就会追踪所有的函数调用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 $ cd /sys/kernel/debug/tracingecho function > current_tracer
向 current_tracer 文件中写入 function_graph,内核就会追踪所有的函数调用,并且将其调用链,函数执行时间都展示出来(这个功能在阅读内核代码的时候极其好用)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 $ cd /sys/kernel/debug/tracingecho function_graph > current_tracerswitch_mm_irqs_off __text_poke __get_locked_pte switch_mm_irqs_off switch_mm_irqs_off
如果通过 echo '*schedule*' > set_ftrace_filter 来设置过滤器,就会发现, cat trace 得到的结果中,果真就是我们想要留下来的满足 *schedule* 这个命名规则的函数。
那么问题来了,ftrace 究竟是如何生效的?我们真的可以为所欲为吗?我们来深入探究一下。
2. ftrace 如何工作? ftrace 的目标是追踪每一个函数,肯定需要 hook 目标函数,并且执行我们自己的逻辑。思路很简单,在每个函数的入口,添加一个 trampoline。
(trampoline 可以翻译为跳板,意思是,这段代码并不直接起作用,只是起到了一个间接跳转的作用)
有了这个 trampoline,我们就可以通过修改 trampoline 中的指令,来跳转到 hook 代码中执行(内核代码也是需要载入内存的,理论上我们可以通过修改这段这块内存,完成各种各样的事情),那么问题来了:添加什么样的 trampoline,又如何添加呢?
这里要感谢编译器提供的一个功能: mcount,即:可以在每个函数执行开始前插入一个叫 mcount 的函数。
2.1 编译器的超能力 2.1.1 用户程序验证 可以通过下面这段程序来验证 mcount 的功能:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include <stdio.h> void mcount () printf ("mcount!\n" );#include <stdlib.h> #include <stdio.h> extern void mcount (void ) void b (int i) printf ("b:%d\n" , i);int a (int i) return 3 ;int main () int i = 3 ;int k = a(i);return k;
首先通过下面三条命令编译 mcount 和主程序
gcc -c main.c -pg
gcc -c mcount.c
gcc mcount.o main.o -o main
然后执行 ./main 执行程序,就会发现,每一个函数调用都会输出 mcount!,Beego!
那么这段程序是如何起作用的呢?注意到,在编译 main.c 的时候,我们加上了一个特殊的编译参数 -pg,这就是告诉编译器:请在函数首部加上 mcount 的调用,接下只需要在链接程序的过程中,提供 mcount 这个函数就好了。
当然,如果不提供 mcount 的实现,也也不会有什么问题,gcc 提供了一个 void __weak mcount(){return;} 作为默认的实现,只有用户没有提供强 mcount 符号的时候才会使用
2.1.2 内核程序验证 内核当中也是这么玩的吗?答案是 YES!
要验证这一点也很容易,只需要通过 gdb 反汇编内核中的函数,就会发现,在这些函数的开头,都插入了一条 call __fentry__ 指令!(PS:暂时不管 __fentry__ 和 mcount 的区别,后续会解释)
1 2 3 4 5 6 7 8 9 10 11 'file vmlinux' -ex 'disassemble schedule' // disassemble 别的函数也是这种结果for function schedule:test %eax,%eax
也就是说,在调用 schedule 函数的核心内容之前,都会调用 __fentry__ 函数,和 mcount 一样,也是一个简单的 retq 指令
1 2 3 4 5 6 7 #ifdef CONFIG_DYNAMIC_FTRACE retq SYM_FUNC_END (__fentry__) EXPORT_SYMBOL (__fentry__)
可以看到,该函数没有什么特别之处,直接 retq 返回。但正因为有了这个额外的 trampoline,让我们能完成很多相当 hack 的事情。
1 2 3 4 5 6 7 8 Tips:
2.1.3 fentry VS mcount 这里来解答刚刚卖下的一个关子,编译器到底用的是 mcount 还是 __fentry__ ?
早些年间,ftrace 确实依赖的 gcc mcount 这个特性,就连处理 mcount 的脚本都称作 readmcount.pl,但是,后来 gcc 将 mcount 改进为了 __fentry__
这两者本质上都是跳板代码,没有特殊的意义(相信你也不会闲到在每一个 mcount 函数中输出 “hello world”),它们的区别在于,mcount 是建立栈帧(stack frame)之后才调用的,这样调用 trampoline 的时候,可能就需要保存一些寄存器,而 fentry 不需要。可以通过 gcc -pg test.c 和 gcc -pg -mfentry test.c 之后,objdump -d a.out 进行查看,显然,fentry 更优
1 2 3 4 5 6 int main () int i = 3 ;return 0 ;
1 2 3 4 5 6 7 8 9 10 11 12 13 0000000000001208 <main>:
2.2 overhead 2.2.1 dynamic vs static 始终铭记一点:计算机世界没有银弹!
如果内核每一个函数开头都加上 call __fentry__ 这个额外的操作,这个开销累积起来是相当可观的。据统计显示,仅仅在 __fentry__ 中使用 retq(没有任何多余的操作),就会增加 13% 的开销(因为几乎每一个函数都有这条指令),显然无法接受!
因此内核开发者想要某种方式,以近乎零成本的方式来完成这件事。怎么做呢?nop 指令!
只需要想办法将所有的 call __fentry__ 转换成 nop 指令,就几乎没有额外的开销,同时,在每一个函数开头也预留了 5个字节的腾挪空间 ,可以将其替换为任意的函数调用指令,理论上就可以完成很多神奇的事情。
并且始终要记住,程序运行在内存中,而内存是可以修改的,更何况内核对于程序的运行情况了如指掌,因此,我们只需要想办法确定所有函数开头的地址即可。显然在编译期间完成这项任务要轻松地多,compiler knows everything!
通过 scripts/recordmcount.c 这个文件 (fentry 仍然沿用了mcount 的一些命名,比如下面的),可以完成下面几件事:
读取所有的二进制 object 文件
读取所有的 relocation table,并且:
找出所有函数中的 call __fentry__ 指令的地址,保存到一个数组中
将这个数组添加到原先的 object 文件中,保存在一个叫做 __mcount_loc 的新 section 中
通过 linker,将 __mcount_loc section 的内容都放在一起,开始和结束的位置分别命名为 __start_mcount_loc __end_mcount_loc
1 2 3 4 5 6 7 // include/asm-generic/vmlinux.lds.h
这样,在 C语言源码中,就能通过 extern unsigned long __start_mcount_loc[]; extern unsigned long __stop_mcount_loc[]; 得到所有调用 call __fentry__ 指令的地址
接下来只需要遍历这个 fentry 数组,将所有对应位置修改为 nop 即可。同时,__mcount_loc 已经光荣地完成了它的使命,不需要出现在最终编译得到的 vmlinux 中了。
这种在启动时候动态替换所有指令的方式,称为 dynamic ftrace,而原先那种带来很多 overhead 的方式,就成为 static tracing。
内核当中通过 CONFIG_DYNAMIC_FTRACE 来控制是否开启动态 ftrace,除了一些和动态追踪的字段需要通过这个编译选项开启,主要是作用于编译期间的一个 FLAG
只有打开了 CONFIG_DYNAMIC_FTRACE,才会开启 BUILD_C_RECORDMCOUNT,才在编译过程中执行 recordmcount ,才会让这些二进制黑魔法得以发挥,否则,啥都不干就只能是 static tracing 了。
1 2 3 4 5 6 ifdef CONFIG_DYNAMIC_FTRACEifdef CONFIG_HAVE_C_RECORDMCOUNTexport BUILD_C_RECORDMCOUNTendif endif
1 2 $(BUILD_C_RECORDMCOUNT) += recordmcount
2.3 stateful vs stateless 刚才已经解决了每个函数开头都要调用 fentry 带来的 overhead,但还不够,因为当我们 trace kernel functions 的时候,是有状态 的!该函数 fentry 是否启用,挂载了多少 trace 回调函数,这些都需要记录下来。因此,Linux 中,对于每一个 call __fentry__ 的地址,都添加了 flags 来标记状态
1 2 3 4 5 6 7 8 9 struct dyn_ftrace {unsigned long ip; unsigned long flags;struct dyn_arch_ftrace arch ;struct dyn_arch_ftrace {
3. ftrace 框架 接下来把目光投向 ftrace 这个框架的启动过程,以及具体的运作。
3.1 ftrace 启动 前面说到,现在已经可以通过 __start_mcount_loc __stop_mcount_loc 两个符号获得所有的 call __fentry__ 指令的地址数组,启动的时候,应该如何将这些指令替换为 nop 呢?
众所周知,在程序运行之后,修改其指令是一件非常危险的事情,因为指令对应的 icache 默认是只读的,所以 CPU 不太会理会你修改之后的内存,仍然会使用位于缓存中预取指令,同时,由于 x86 的指令长度非常不一致,导致一条指令可能跨越缓存行/内存页,在 SMP 系统中,更需要精确控制,才不会产生不一致行为(导致 CPU 执行出错,reboot)
Linux 也为修改 text 提供了很多实用的 API,比如这里用到的 text_poke_early,就在 memcpy 之后通过 sync_core 进行同步,正如其文档所说,强制 icache 更新到当前修改过后的指令(通过 inter-process interrupt)
1 2 3 4 5 6 7 8 9 * This function forces the icache and prefetched instruction stream to
1 2 3 4 5 6 7 8 9 10 11 void __init_or_module text_poke_early (void *addr, const void *opcode, size_t len) unsigned long flags;memcpy (addr, opcode, len);
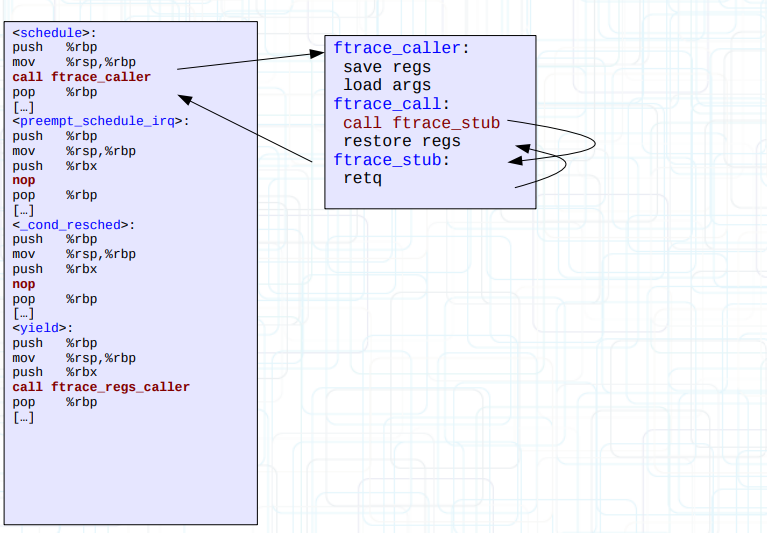
3.2 trampoline 实际使用的时候,并不是通过直接将函数开头 5 bytes 的 nop 替换为 call target_ip,而是通过下面这段 trampoline 进行间接调用
不修改 call ftrace_stub 这条指令的话,执行顺序如下面标注所示,不得不说,设计得还是非常考究的,巧妙地利用了 call 和 retq 的特性,虽然也还有很多别的设计方式了
1 2 3 4 5 6 7 8 ftrace_caller:
这段 assembly 代码位于 arxh/x86/kernel/ftrace_64.S,是一段模板代码,实际使用的时候,会在 register_ftrace_function 的时候,通过 ops->trampoline = create_trampoline(ops, &size) 创建和上面这段几乎一样的跳板代码,然后将函数开头的 nop 指令替换为 call xxx,xxx 就是目标函数地址
其实,这里还做了一层封装,并不是直接将 xxx 设置为目标函数地址,因为那样根本无法扩展,实际中,如果想要在一个 fentry 点注册多个回调函数,只能将其保存在一个链表中,依次调用。
因此,ftrace_stub 最终会被替换为两种 wrapper 函数,一个是 ftrace_ops_list_func,另一个是 ftrace_ops_assist_func,或者就直接设置为 ops->func 也是有可能的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ftrace_func_t ftrace_ops_get_func (struct ftrace_ops *ops) if (!(ops->flags & FTRACE_OPS_FL_RECURSION_SAFE) ||return ftrace_ops_assist_func;return ops->func;static ftrace_func_t ftrace_ops_get_list_func (struct ftrace_ops *ops) if (ops->flags & (FTRACE_OPS_FL_DYNAMIC | FTRACE_OPS_FL_RCU) ||return ftrace_ops_list_func;return ftrace_ops_get_func(ops);
ftrace_ops_list_func 则直接调用了 __ftrace_ops_list_func,主要的操作是,遍历 ftrace_ops_list 中的每一个 op,依次调用其 op->func
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 static nokprobe_inline void unsigned long ip, unsigned long parent_ip,struct ftrace_ops *op ;if (op->flags & FTRACE_OPS_FL_STUB)continue ;if ((!(op->flags & FTRACE_OPS_FL_RCU) || rcu_is_watching()) &&if (FTRACE_WARN_ON(!op->func)) {"op=%p %pS\n" , op, op);goto out;
因此,只需要在给 function 注册 ftrace op 的时候,提前判断一下是否已经有注册的 op,即可选择合适的 wrapper 函数
3.3 preemption 对于这种 dynamic trampoline 来说,有一个问题必须要解决,那就是抢占
因为这里的 trampoline 是动态创建的,一旦这个 fucntion 所有注册的 op 都释放了,就理所应当调用 kfree(trampoline) 来释放这段空间,但是,由于抢占的关系,无法确保这一点,这就引入了 RCU
具体的机制我暂时也没太搞明白,留个坑,慢慢补。