1. netfilter 简介 1.1 什么是 netfilter 如今的 netfilter 遍布 Linux network system 的各个角落,我们首先来回顾一下其发展历史。
早些的 Linux 版本中,也存在用来进行 ip 过滤、管理等操作的框架,不论是 ipchains 还是 ipfwadm(ip firewall admin),功能都比较局限。直到 netfilter 出现,作为一个统一且易于扩展的框架,应用到内核当中。
netfilter 允许用户注册各种回调函数,并且在特定的场合(netfilter hooks)按照特定的条件触发,在内核收发 skb 数据包的链路中,存在多处这样的 hook,不仅可以用来记录连接信息(logging),甚至可以更改 skb 头部的一些字段(mangle),更改 ip 地址(NAT),丢弃数据包(防火墙)
1.2 思路 netfilter 是内核中的一个重要模块,同时也需要和用户程序进行交互,因此下面分为两大部分进行讲解:
netfilter 功能,如 NAT,修改数据包头部,连接追踪,包过滤,网络统计等
iptables 如何起作用的
2. netfilter 框架 刚刚讲到,netfilter 通过不同的 hook 生效,首先就来看究竟有哪些 hooks
2.1 netfilter hooks 在 include/uapi/linux/netfilter.h 中,定义了下面的五种最广为人知的 hooks
enum nf_inet_hooks {
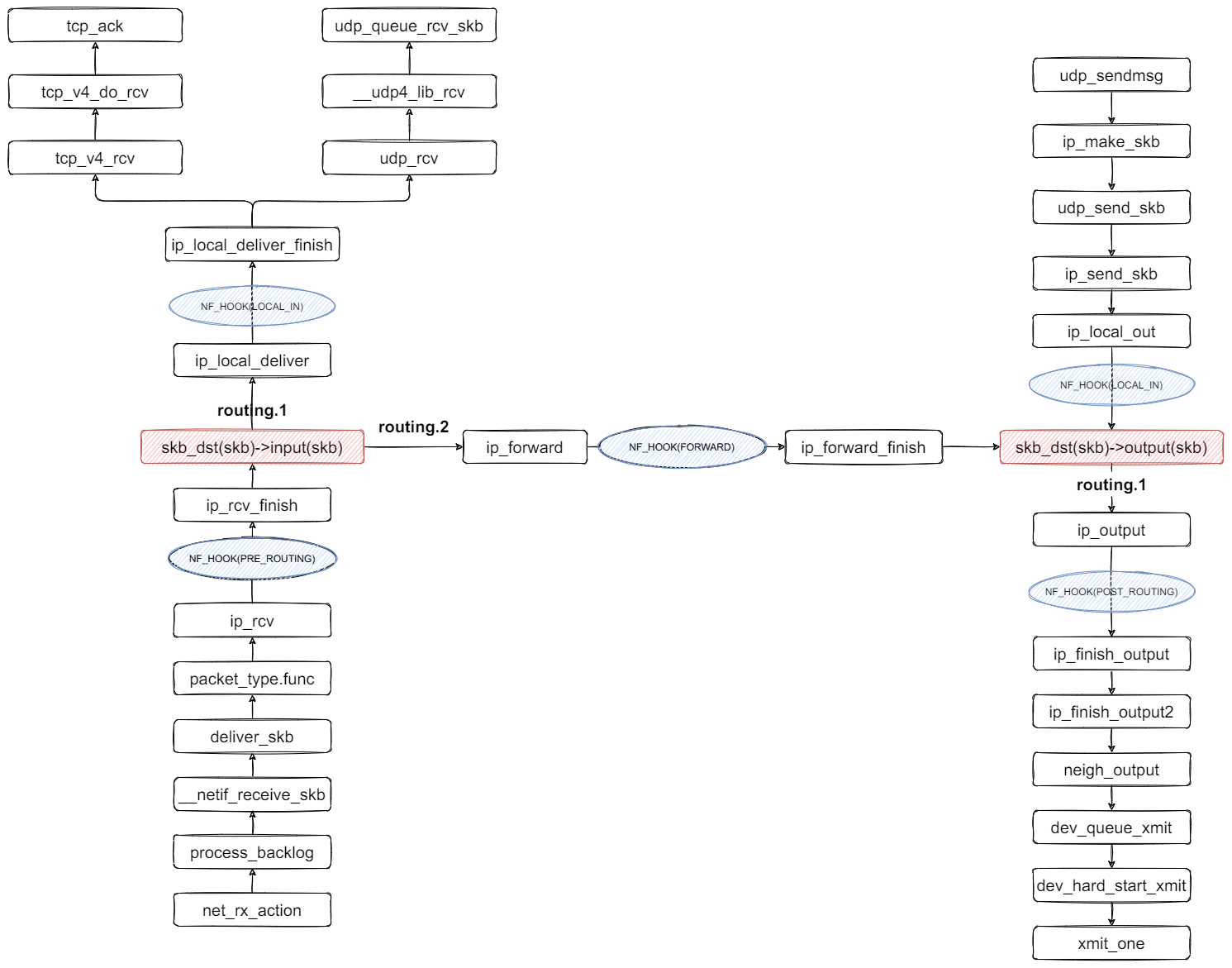
对上面几个 hook 类型不熟悉也没关系,可以先结合下面这张内核收发包路径图强化一下认识:
netfilter 框架提供了一种比较便捷的使用 hooks 的方式:NF_HOOK
1 2 3 4 5 6 7 8 9 10 static inline int NF_HOOK (uint8_t pf, unsigned int hook, struct net *net, struct sock *sk, struct sk_buff *skb, struct net_device *in, struct net_device *out, int (*okfn)(struct net *, struct sock *, struct sk_buff *)) int ret = nf_hook(pf, hook, net, sk, skb, in, out, okfn);if (ret == 1 )return ret;
解释一下这里的参数:
pf:protocol family,即 ipv4 或 ipv6
hook:hook 类型,可以参考上面的 enum nf_inet_hooks
skb:当前正在处理的数据包
in:网络输入设备
out:网络输出设备
okfn:该 hook 结束时调用的函数,仅接收 skb 作为参数
这个函数返回 nf_hook 的结果,nf_hook 中,就是简单判定一下 hook 类型,取出对应的回调函数,交给 nf_hook_slow 进行处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 static inline int nf_hook (u_int8_t pf, unsigned int hook, struct net *net, struct sock *sk, struct sk_buff *skb, struct net_device *indev, struct net_device *outdev, int (*okfn)(struct net *, struct sock *, struct sk_buff *)) struct nf_hook_entries *hook_head =NULL ;int ret = 1 ;switch (pf) {case NFPROTO_IPV4:break ;case NFPROTO_IPV6:break ;default :1 );break ;if (hook_head) {struct nf_hook_state state ;0 );return ret;
最终该函数返回一个表示处理状态的值,有下面几个选项:
NF_DROP 丢弃数据包
NF_ACCEPT 接受数据包
NF_STOLEN 数据包被抢占
NF_QUEUE 将数据包放入队列
NF_REPEAT 该 hook 函数应该重新调用
具体使用时候就很简单了:
1 2 3 4 5 6 7 8 9 10 11 12 13 int ip_rcv (struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *orig_dev) struct net *net =if (skb == NULL )return NET_RX_DROP;return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING,NULL , skb, dev, NULL ,
比如上面的 ip_rcv,传入必要的参数,以及 ip_rcv_finish 这个 okfn,从而在该 hook 执行结束之后接着通过 ip_rcv_finish 处理 skb 数据包。
2.2 netfilter registration 不论有多少 hook,最终还是由用户的回调函数来决定具体的操作(框架+机制),那么回调函数是如何注册的呢?先来看 nf_hook_ops 结构
1 2 3 4 5 6 7 8 9 10 11 12 13 14 typedef unsigned int nf_hookfn (void *priv, struct sk_buff *skb, const struct nf_hook_state *state) struct nf_hook_ops {struct net_device *dev ;void *priv;u_int8_t pf;unsigned int hooknum;int priority;
来看几个重要字段的含义:
hook:回调函数
dev:设备
pf:协议族,可以参考上面的 enum nf_inet_hooks
priority:优先级,所有 nf_hook_ops 按照从小到大的顺序组织,数值越小,优先级越高
有两个函数可以注册 hook:
nf_register_net_hook
nf_register_net_hooks
后者其实只是传入一个 nf_hook_ops 数组,循环调用 nf_register_net_hook 罢了,前者最核心的处理逻辑在于传入旧的 nf_hook_entries 列表以及新添加的 nf_hook_ops,并返回一个新的 nf_hook_entries 列表,我们来看一下具体实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 static const struct nf_hook_ops dummy_ops =static struct nf_hook_entries *nf_hook_entries_grow (const struct nf_hook_entries *old, const struct nf_hook_ops *reg) unsigned int i, alloc_entries, nhooks, old_entries;struct nf_hook_ops **orig_ops =NULL ;struct nf_hook_ops **new_ops ;struct nf_hook_entries *new ;bool inserted = false ;1 ;0 ;if (old) {for (i = 0 ; i < old_entries; i++) {if (orig_ops[i] != &dummy_ops)if (alloc_entries > MAX_HOOK_COUNT)return ERR_PTR(-E2BIG);new = allocate_hook_entries_size(alloc_entries);if (!new )return ERR_PTR(-ENOMEM);new );0 ;0 ;while (i < old_entries) {if (orig_ops[i] == &dummy_ops) {continue ;if (inserted || reg->priority > orig_ops[i]->priority) {void *)orig_ops[i];new ->hooks[nhooks] = old->hooks[i];else {void *)reg;new ->hooks[nhooks].hook = reg->hook;new ->hooks[nhooks].priv = reg->priv;true ;if (!inserted) {void *)reg;new ->hooks[nhooks].hook = reg->hook;new ->hooks[nhooks].priv = reg->priv;return new ;
nf_hook_entries_grow 大致可以分为两个部分:
计算需要分配的空间
按照 priority 将 reg 插入到合适的位置
可以看出,alloc_entries 表示的分配表项数目为 1 + num_of_old_entries,其中 num_of_old_entries 则是原有表项数目。之所以要与 dummy_ops 进行比较,是因为 dummy_ops 并不消耗空间,只需要一个指针指向其即可,分配空间处理的是那些有意义的表项
根据 priority 插入 reg 的过程也挺简单,和插入排序比较相似,只不过这里不仅需要插入一个表项,还需要按序将旧表中的所有内容拷贝过来,再重新体会一下上面的代码,应该比较容易理解。
2.3 netfilter front end - iptables iptables 作为 netfilter 的前端,在内核中分别对应 ipv4 和 ipv6 的实现,这里只讨论前者的实现机制。
为了与用户空间进行交互,iptables 使用了 struct xt_table 进行表示,拿过滤数据包的表格为例:
1 2 3 4 5 6 7 8 9 10 11 12 #define FILTER_VALID_HOOKS ((1 << NF_INET_LOCAL_IN) | \ (1 << NF_INET_FORWARD) | \ (1 << NF_INET_LOCAL_OUT)) static const struct xt_table packet_filter ="filter" ,
之前也都接触过类似于 name,me,af,priority 这样的字段,这里不必多言,重心放在 table_init 对应的 iptable_filter_table_init 回调函数上
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 static int __net_init iptable_filter_table_init (struct net *net) struct ipt_replace *repl ;int err;if (net->ipv4.iptable_filter)return 0 ;return err;
这里就是典型的三步走:
判断是否已经初始化完成
未初始化则首先分配空间
调用对应的注册函数
再来看 ipt_register_table,该函数主要做了四件事:
分配新表所用内存
将 table 注册到 net->xt.tables 结构中
设置 net->ipv4.xxx_table 为传入的 ops
注册 netfilter hooks
也就是说,不仅要完成和 iptables 相关的注册,也要完成 netfilter 相关的注册。
之后的很多关键回调操作,其实都会根据已经设置的 net->ipv4.xxx_table 进行相应回调
1 2 3 4 5 6 static unsigned int iptable_nat_do_chain (void *priv, struct sk_buff *skb, const struct nf_hook_state *state) return ipt_do_table(skb, state, state->net->ipv4.nat_table);
很多人可能还会好奇,iptables 这条命令是如何与内核进行交互的呢?通过 strace iptables -nvL 可以发现,用到了名为 getsockopt 的系统调用。
顺着这条线索,可以去查看和 iptables 相关的 .getsockopt && .setsockopt 回调函数,果然发现了 nf_getsockopt 以及 nf_setsockopt,只不过这两个函数是在 ip_getsockopt 和 ip_setsockopt 中被调用的,其函数调用链如下:
1 2 3 4 5 sys_getsockopt
在 nf_sockopt_ops->get 对应的 do_ipt_get_ctl 操作中,会根据用户输入指令派发相应的操作。同理,do_ipt_set_ctl 的逻辑可能要稍复杂一些,不过根据前面的知识,相信你也能啃下这块骨头,其源码位于 net/ipv4/netfilter/ip_tables.c。
还有一点值得一提,那就是 nf_sockopt_ops 其实是针对网络各个协议表格的统一抽象,除了 iptables,其它的比如 arptables,ip6tables,ebtables 等等,也都有其对应的 nf_sockopt_ops 结构体,并且可以通过 nf_register_sockopt 注册到系统中,然后通过 nf_sockopt_find 查询出来并加以使用。这种抽象大大降低了编码复杂度,并且可以更加有序地管理各种表格。
2.3 netfilter 功能 接下来的几个小节,都是对 netfilter 的具体功能进行讲解。
首先要明确 netfilter 框架为我们提供了什么,然后才能利用好它。
netfilter 框架可以简化为 hooks + 回调函数 ,那么如果想要在网络收发包路径上的特定位置,做一些特殊操作,注册回调函数就好了嘛。hooks 不仅可以由用户在内核运行时注册,还可以直接在源码中声明并注册,拿来即用。
2.3.1 Connection Tracking TODO
2.3.2 NAT NAT 即 network address translation,网络地址转换,也是通过注册 nf_hook_ops 来实现,对应下面这些 ops
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 static const struct nf_hook_ops nf_nat_ipv4_ops [] =
在四个 hook 点对应关系如下:
PRE_ROUTING – nf_nat_ipv4_in
POST_ROUTING – nf_nat_ipv4_out
LOCAL_OUT – nf_nat_ipv4_local_fn
LOCAL_IN – nf_nat_ipv4_fn
模块初始化时,会通过 nf_nat_register_fn 注册这四个 nf_hook_ops,这里不再赘述。
经过层层调用,最终会根据协议类型,调用相应的 manipulate 函数,比如 tcp 对应 tcp_manip_pkt,udp 对应 udp_manip_pkt …… 调用链如下:
1 2 3 4 5 6 7 nf_nat_inet_fn
在 Layer4 相关的协议中,还需要进一步判断到底是 DNAT 还是 SNAT,判断逻辑如下
1 2 3 4 5 6 7 8 9 if (maniptype == NF_NAT_MANIP_SRC) {else {
修改完数据包的头部之后,切记还要更新 checksum,不然等待数据包的只有无尽的 checksum error。
2.4.2 Firewall 防火墙其实是相对比较简单的功能了,因为它只是通过某些特定条件,判定数据包是否需要被拦截,如果需要被拦截,则直接返回 NF_DROP 即可,否则啥都不做就好。
同时,大部分防火墙规则是用户自定义的,并不由 Linux 本身提供,因此这里也不必多言。