1. what’s neighbouring subsystem
邻居子系统是网络协议栈必不可少的一环,主要负责将 L3(network layer)地址转换为 L2(link layer)地址。
为了实现这个功能,Linux 实现了 Arp 协议(ipv4)以及 Neighbour Discovery Protocol(ipv6)。本章只会讨论 Arp 协议相关的内容。首选会介绍一下几个重要的数据结构,然后再根据协议栈汇总收发包的路径进行串讲。
2. neighbouring subsystem internal
2.1 more details
当数据包经过 L2 时,需要 L2 目标地址,从而填充 L2 header,通过 neighbouring subsystem,可以通过 L3 地址来进行查询对应的 L2 地址,如果查不到,还可以发送 solicitation 数据包,通过 Arp 协议请求别的设备完成地址解析并相应该请求。
我们绝大部分使用的都是 Ethernet,因此 L2 的目标/源地址都是 MAC 地址。
2.2 data structure
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
| struct neighbour {
struct neighbour __rcu *next;
struct neigh_table *tbl;
struct neigh_parms *parms;
unsigned long confirmed;
unsigned long updated;
rwlock_t lock;
refcount_t refcnt;
unsigned int arp_queue_len_bytes;
struct sk_buff_head arp_queue;
struct timer_list timer;
unsigned long used;
atomic_t probes;
__u8 flags;
__u8 nud_state;
__u8 type;
__u8 dead;
u8 protocol;
seqlock_t ha_lock;
unsigned char ha[ALIGN(MAX_ADDR_LEN, sizeof(unsigned long))] __aligned(8);
struct hh_cache hh;
int (*output)(struct neighbour *, struct sk_buff *);
const struct neigh_ops *ops;
struct list_head gc_list;
struct rcu_head rcu;
struct net_device *dev;
u8 primary_key[0];
} __randomize_layout;
关键字段的含义:
1. next:neighbour 在哈希表中的下一个节点
2. tbl:neighbour 所在的 neigh_table
3. confirmed:neighbour 的验证时间(arp 协议)
4. timer:对应 neigh_timer_handler 回调函数,会定时判定该 neighbour 的 Neighbour Unreachability Detection State(NUD)
5. ha:neighbour 的硬件地址
6. hh:L2 头部信息缓存
7. nud_state:Neighbour Unreachability Detection State(NUD),会随着时间动态更新
8. dead:neighbour 是否已经失效
9. primary_key:neighbour 的 L3 地址,用于在 neigh_table 中进行哈希查找
struct neigh_table {
int family;
unsigned int entry_size;
unsigned int key_len;
__be16 protocol;
__u32 (*hash)(const void *pkey,
const struct net_device *dev,
__u32 *hash_rnd);
bool (*key_eq)(const struct neighbour *, const void *pkey);
int (*constructor)(struct neighbour *);
int (*pconstructor)(struct pneigh_entry *);
void (*pdestructor)(struct pneigh_entry *);
void (*proxy_redo)(struct sk_buff *skb);
int (*is_multicast)(const void *pkey);
bool (*allow_add)(const struct net_device *dev,
struct netlink_ext_ack *extack);
char *id;
struct neigh_parms parms;
struct list_head parms_list;
int gc_interval;
int gc_thresh1;
int gc_thresh2;
int gc_thresh3;
unsigned long last_flush;
struct delayed_work gc_work;
struct timer_list proxy_timer;
struct sk_buff_head proxy_queue;
atomic_t entries;
atomic_t gc_entries;
struct list_head gc_list;
rwlock_t lock;
unsigned long last_rand;
struct neigh_statistics __percpu *stats;
struct neigh_hash_table __rcu *nht;
struct pneigh_entry **phash_buckets;
};
|
关键字段含义:
- next:每一个 L2 协议都会创建自己的 neigh_table,因此需要通过链表来进行管理
- family:protocol 协议簇,AF_INET 表示 ipv4,AF_INET6 表示 ipv6
- entry_size,key_len,hash:哈希表有关的配置
- constructor,pconstructor,pdestructor:neighbour 的初始化以及析构函数
- id:neigh_table 的名称
- params:neigh_table 的配置,包含了很多属性
- phash_buckets:哈希表(哈希桶 + 链表)
neighbour 作为哈希表的 value 存在于 neigh_table 当中,而哈希表的 key 就是 L3 地址。因此通过 skb ip头中的目标地址,可以快速找到对应的 neighbour。
2.3 从 Layer3 到 Layer2
发送数据包时,要通过下面的函数调用链
1
2
3
4
5
6
| ip_local_out
--> ip_output
--> ip_finish_output
--> ip_finish_output2
--> neigh_output
--> dev_queue_xmit
|
其中,从 L3 到 L2 的转换对应 ip_finish_output2 中 neigh_output 的调用。下面来看具体实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| static int ip_finish_output2(struct net *net, struct sock *sk, struct sk_buff *skb)
{
struct dst_entry *dst = skb_dst(skb);
struct rtable *rt = (struct rtable *)dst;
struct net_device *dev = dst->dev;
unsigned int hh_len = LL_RESERVED_SPACE(dev);
struct neighbour *neigh;
bool is_v6gw = false;
rcu_read_lock_bh();
neigh = ip_neigh_for_gw(rt, skb, &is_v6gw);
if (!IS_ERR(neigh)) {
int res;
sock_confirm_neigh(skb, neigh);
res = neigh_output(neigh, skb, is_v6gw);
rcu_read_unlock_bh();
return res;
}
rcu_read_unlock_bh();
}
|
ip_finish_output2 中首先通过 ip_neigh_for_gw 获取了 neigh,然后调用 neigh_output 进入 Layer2 并完成后续的操作。前者其实非常简单,最后调用了下面的函数进行查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
\*
ip_neigh_for_gw
--> ip_neigh_gw4
--> __ipv4_neigh_lookup_noref
--> ___neigh_lookup_noref
*\
static inline struct neighbour *___neigh_lookup_noref(
struct neigh_table *tbl,
bool (*key_eq)(const struct neighbour *n, const void *pkey),
__u32 (*hash)(const void *pkey,
const struct net_device *dev,
__u32 *hash_rnd),
const void *pkey,
struct net_device *dev)
{
struct neigh_hash_table *nht = rcu_dereference_bh(tbl->nht);
struct neighbour *n;
u32 hash_val;
hash_val = hash(pkey, dev, nht->hash_rnd) >> (32 - nht->hash_shift);
for (n = rcu_dereference_bh(nht->hash_buckets[hash_val]);
n != NULL;
n = rcu_dereference_bh(n->next)) {
if (n->dev == dev && key_eq(n, pkey))
return n;
}
return NULL;
}
|
___neigh_lookup_noref 函数完成了一个简单的 hash_bucket 查询:计算出 hash_val,取出 hash_val 对应的链表,遍历链表,并按照 key_eq 函数判定哈希值是否相等。
有了 neigh 之后,就可以根据这个邻居开始真正的邻居子系统之旅,接下来的 neigh_output 函数中有两条路径,分别为 neigh_hh_output 和 neighbour->output,跟踪源码,前者最终会调用 dev_start_xmit 进入驱动层发送数据包,而后者在这里对应 neigh_resolve_output
1
2
3
4
5
6
7
8
9
10
| static inline int neigh_output(struct neighbour *n, struct sk_buff *skb,
bool skip_cache)
{
const struct hh_cache *hh = &n->hh;
if ((n->nud_state & NUD_CONNECTED) && hh->hh_len && !skip_cache)
return neigh_hh_output(hh, skb);
else
return n->output(n, skb);
}
|
关键点在于,何时直接发送数据包?何时调用 output 回调函数?这主要是由 n->nud_state 决定的。nud_state 从何而来,那就不得不提 Arp 协议的实现了
2.4 Arp 协议
前面说到,neigh_output 需要根据 nud_state 选择一个合适的分支,这一步很关键,只有当状态为 NUD_CONNECTED 时才会通过该邻居发送数据包。
nud_state 全称为 Neighbour Unreachability Detection State,也就是 Arp 协议解析的状态,其中,NUD_CONNECTED 表示已经建立连接,NUD_STALE 表示已经过期,NUD_DELAY 表示延迟到期,NUD_PROBE 表示正在探测,NUD_FAILED 表示失败。只有当 neighbour 处于 NUD_CONNECTED 状态时,表示该邻居是可达的,才能继续发送数据包,否则需要通过 Arp 协议更新状态,直到状态转换为 NUD_CONNECTED 才能重新发送。
ARP 协议中用到的状态完整定义如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| #define NUD_INCOMPLETE 0x01
#define NUD_REACHABLE 0x02
#define NUD_STALE 0x04
#define NUD_DELAY 0x08
#define NUD_PROBE 0x10
#define NUD_FAILED 0x20
#define NUD_NOARP 0x40
#define NUD_PERMANENT 0x80
#define NUD_NONE 0x00
#define NUD_IN_TIMER (NUD_INCOMPLETE|NUD_REACHABLE|NUD_DELAY|NUD_PROBE)
#define NUD_VALID (NUD_PERMANENT|NUD_NOARP|NUD_REACHABLE|NUD_PROBE|NUD_STALE|NUD_DELAY)
#define NUD_CONNECTED (NUD_PERMANENT|NUD_NOARP|NUD_REACHABLE)
|
ARP 协议最复杂的地方也在于此,需要一个完备的状态机,才不至于迷失在各种状态的转化中。
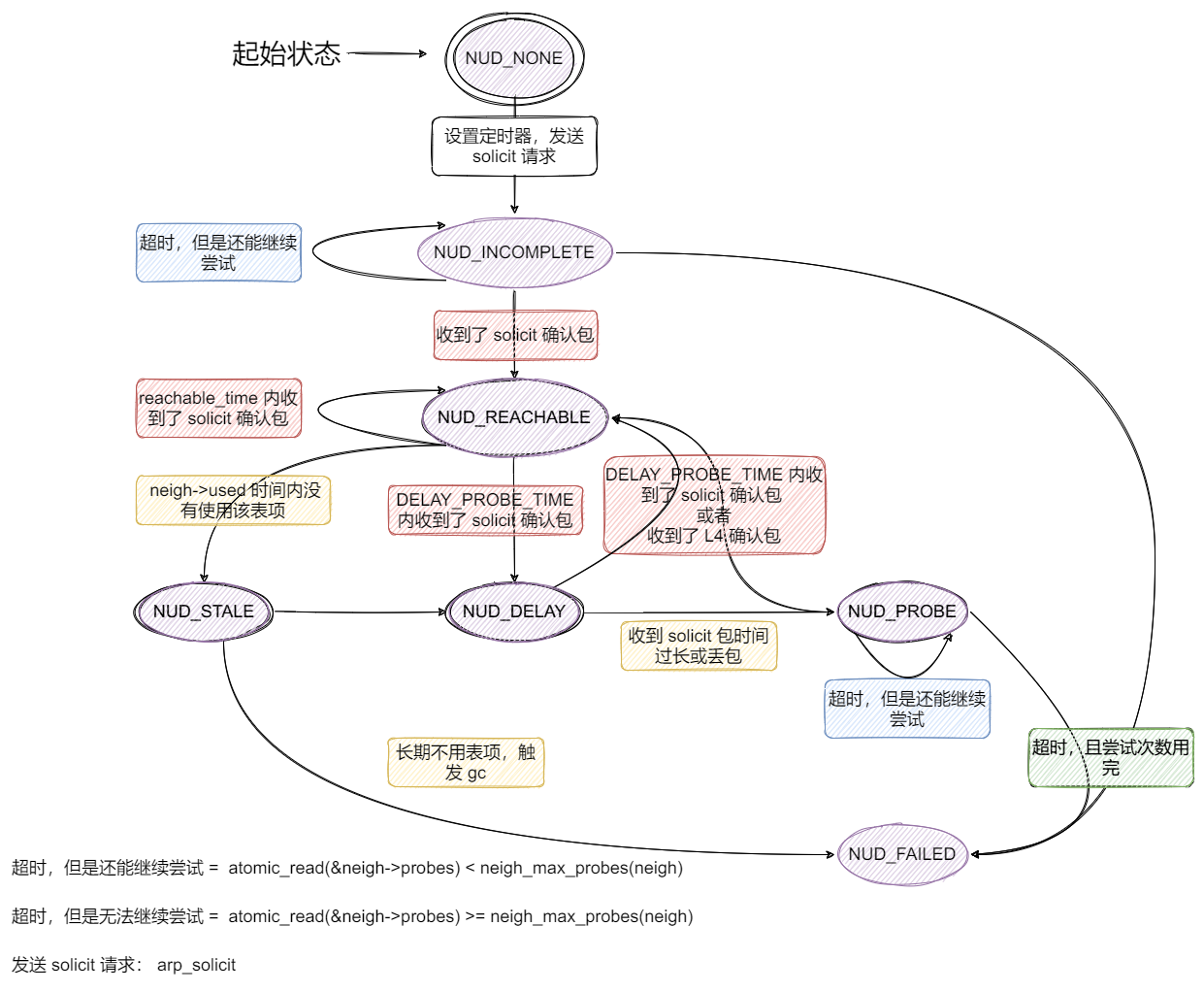
- 如何转换为
NUD_REACHABLE 状态?
NUD_REACHABLE 约等于 NUD_CONNECTED,如果该状态的 neighbour 是可以发送数据包的,同时,其状态也会缓存下来
有两个方式可以转换到该状态:1) 发送 solicit 数据包,并在规定时间内收到了肯定应答;2) 收到了上层协议的确认包
- 如何转换为
NUD_INCOMPLETE 状态?
NUD_INCOMPLETE 表示已经发送了 solicit 数据包,但是还没有收到应答,此时无有效的 Layer2 Address
NUD_INCOMPLETE 只能从初始的 NUD_NONE 而来,最终也只能转换为 NUD_FAILED 状态
NUD_STALE NUD_DELAY NUD_PROBE 状态表示什么?
NUD_STALE 表示虽然已经缓存 neighbour 信息,但是已经过期,当 neighbour 位于这个状态时,会在下一次发送数据包时触发 reachability 的检测,并且转换为 NUD_DELAY 状态
NUD_DELAY 表示一个可以等待 reachability 确认的时间窗口,当完成了 solicit 确认之后,也会转换为 NUD_INCOMPLETE 状态
位于 NUD_DELAY 超出容忍的最长时间之后,会进入到 NUD_PROBE 状态,此时,会像 NUD_INCOMPLETE 一样循环发送 solicit 数据包,等待应答或者直到发送次数用完,表明本次 Arp 请求失败
2.5 用户与 neighbouring subsystem 交互
在讲解 netlink 的时候提到过,NETLINK_ROUTE 不仅包含了路由子系统,还包含了邻居子系统,因此,和 neighbour 相关的操作也是通过 rtnetlink 暴露出去的。
1
2
3
4
5
6
7
8
9
10
11
12
| static int __init neigh_init(void)
{
rtnl_register(PF_UNSPEC, RTM_NEWNEIGH, neigh_add, NULL, 0);
rtnl_register(PF_UNSPEC, RTM_DELNEIGH, neigh_delete, NULL, 0);
rtnl_register(PF_UNSPEC, RTM_GETNEIGH, neigh_get, neigh_dump_info, 0);
rtnl_register(PF_UNSPEC, RTM_GETNEIGHTBL, NULL, neightbl_dump_info,
0);
rtnl_register(PF_UNSPEC, RTM_SETNEIGHTBL, neightbl_set, NULL, 0);
return 0;
}
|
例如 ip neigh show 这条指令,就对应了 neigh_dump_info 这个回调函数。
如果想进一步深入了解,可以在掌握了 netlink 的基础上,通过 strace/funcgraph 等工具来进行内核代码追踪,相信你能有更加深刻的理解。
