netlink
1. netlink 简介
1.1 netlink 是什么
netlink 是一种 进程间通信(inter process communication IPC) 机制,为用户空间和内核空间进程之间(当然也可以是两个内核进程之间)提供了一种双向异步的通信方式。
netlink 依托成熟的 socket api 提供服务,增加了 AF_NETLINK 这个协议簇,依靠 sock_ops 对应的各种回调函数(sendmsg,recvmsg)来实现 netlink 的功能。
1.2 netlink 优点
相比如其他的 IPC 方式,netlink 有下面几点优势:
- 不需要通过 poll 操作来获取数据,像普通 socket 编程一样 recvmsg 即可,接口简单
- 全双工异步通信
- netlink 支持广播和多播
1.3 netlink 示例
前面说到,netlink 通过 socket 向用户提供操作接口,具体应该怎么用呢?下面是其工作示意图
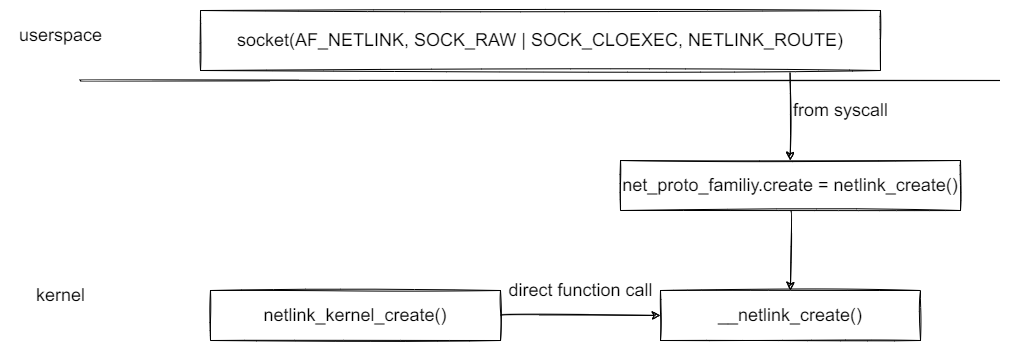
2. netlink internal
2.1 netlink api
前面说到,可以用 socket api 来操控 netlink,我们就从 socket(AF_NETLINK, SOCK_RAW, NETLINK_ROUTE) 的几个参数入手
- AF_NETLINK,指定该 socket 的协议簇为 NETLINK,这样能通过
netlink_family_ops.create回调函数创建 socket 的内部结构
1 | |
- SOCK_RAW,与主题无关,暂不讨论
- NRETLINK_ROUTE,指定 NETLINK 的类型,因为 NETLINK 在内核中被各个模块使用,所以需要通过这个字段区分究竟是哪个模块,而 netlink socket 相当于一个多路复用器,通过在内核中保存的一个针对不同 protocol 的 netlink_table,查表就能获取到对应的回调函数。
1 | |
1 | |
2.2 netlink’s protocols
下面来看一下 netlink 处理不同 protocol 的方式
netlink 通过 netlink_kernel_create 来初始化一种 protocol,该函数接收三个参数:
- net:network namespace
- unit:也就是将 protocol 作为 netlink_table 的下标,
- cfg:配置选项,提供 input/bind/unbind 等回调函数,以及别的一些配置信息,保存到 nl_table 中
也就是说,netlink 将 protocol 作为 nl_table 的下标,不同的 protocol 提供不同的 cfg 即可,这是一种典型的策略模式,下面分别是 NETLINK_ROUTE 和 NETLINK_KOBJECT_UEVENT 两种 protocol 对应的初始化函数,so easy
1 | |
1 | |
2.3 deeper into netlink’s api
前面提到,通过 socket api 可以直接操作 netlink,那具体到每种操作,对应怎样的内核执行路径呢?下面来进行探究
- sendmsg 系统调用
1 | |
sys_sendmsg 最终会调用到 sock_ops->sendmsg,从而触发 AF_NETLINK 对应的 netlink_sendmsg 回调函数。
前面也说到,netlink 可以对应单播或者广播,这里以 unicast,也就是单播的执行路径为例,最终触发了 cfg->input 中传入的 rev 函数,对于 rtnetlink 而言,就会调用 rtnetlink_rcv。
1 | |
- recvmsg 系统调用
1 | |
在 rtnl_get_link 这一步,会根据传入的下标取出 rtnl_msg_handlers 数组中的 link,从而执行 link->doit 回调函数
而该数组中的内容是系统初始化时就设置好的,在 rtnetlink_init 中,通过 rtnl_register 初始化了一系列操作对应的处理函数
1 | |
rtnl_register 函数原型为:
1 | |
几个参数的含义分别为:
- protocol:具体的协议
- msgtype:消息类型,后面会提到
- doit:注册到 rtnl_msg_handlers 中的 link->doit
- dumpit:注册到 rtnl_msg_handlers 中的 link->dumpit
- flags:doit/dumpit 的参数
rtnetlink 字面意思是 route table netlink,其实它包含的范围更大,邻居子系统也是通过 rtnetlink 暴露出去的,都可以从上面的 msgtype 参数可以看出来。
这样解释还是有一些抽象,但其实 Linux 中一些网络相关的常用指令都是以 rtnetlink 为基础,就比如 ip addr show
这条指令,会显示所有网络设备的地址信息,背后就是调用了 msgtype 为 RTM_GETADDR 的 rtnl_dump_all ,通过 funcgraph 可以查看详细的内核函数调用链,从而验证这一点。
事实上,NETLINK_ROUTE 可以按照下面进行划分:
- LINK (network interfaces)
- ADDR (network addresses)
- ROUTE (network messages)
- NEIGH (neighbouring subsystem messages)
- RULE (policy rouing rules)
- QDISC (queueing disciplines)
- TCLASS (traffic classes)
- ACTIOn (packet action api)
- NEIGHTBL (neighbouring table)
- ADDRLABEL (address labeling)
不仅是路由子系统,几乎所有 L3 和 L2 的功能,都通过 rtnetlink 暴露出去
3. generic netlink protocol
netlink 协议簇数最大 32 个(MAX_LINKS),为支持更多的协议簇,开发了通用 netlink 簇 NETLINK_GENERIC。generic netlink 以 netlink 协议为基础,多做了一层多路复用,从而能够支持更多的子系统(netlink 本身已经完成了一次多路复用)。
同理,generic netlink 也需要通过 netlink_kernel_create 初始化:
1 | |
也就是说,generic netlink socket 的 nlk->netlink_rcv 会对应 genl_rcv,在这个函数中,主要是查找对应的 generic family,然后调用其对应的 doit 回调函数。
这一点其实不难理解,netlink 本身支持多种协议簇,所以维护了一张 nl_table,保存了所有协议对应的处理方式,以 protocol 作为下标,取出对应的协议回调函数即可,这是第一层多路复用。
而 generic netlink 在这个基础上进一步维护了多路复用,同理也是维护一张表格,通过二级协议类型 genl_family 作为下标,道理其实非常相似。
genl_family 可以通过 genl_register_family/genl_unregister_family 进行注册和注销。
只不过有一点不大一样,genl_family 用到了 struct idr 这个结构,相比数组而言更加灵活,这里不过多赘述。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!
