internship
1. why do i write this?
哎,老了,记忆力不行了,几个月前的实习经历已经忘得差不多了,但在我潜意识里,我认为自己可以很好得讲述当时的技术细节,这种落差带了一个非常严重的后果:面试时对于实习期间所学一问三不知。
所以,想在这里稍微针对简历中的 internship 经历和学习到的知识点做一个简单的记录和梳理
2. 实习经历
2.1 字节跳动-财经部-自有支付-实习生
2.1.1 闲谈
还记得这份工作当时也准备了蛮久,最终在腾讯与字节中选择了后者。
这个地方第一次让我认识到了大厂是一个什么样的工作环境,以及这里的人是什么样的工作状态。大家看起来还蛮轻松的,桌子上满满当当的饮料和零食,一时间竟觉得来到了天堂。不过,后来也慢慢认清了现实:工作时间是真久啊,会议室真难订啊,周末是真没精力学习啊。
不过也收获了很多知识吧,下面一一说明
2.1.2 Golang 知识
众所周知,字节 70% 的业务在用 Golang 开发,上手的第一件事就是认真学习 Golang。得益于之前学习 Linux 的一些经验,看起框架源码和 Golang 源码也不算太吃力。借助内部丰富的学习资源,很快也就掌握了其使用。Golang 里面最吸引我的是 CSP 模型以及底层的 goroutine 和 channel 的使用,本着掘地三尺的精神,我深扒了其源码,总算有了一些头绪。
2.1.2.1 goroutine && Scheduler
Golang 在并发编程上有很大的能力,得益于其底层对于并发的支持,最值得一提的当然是 goroutine 的设计。但是这里首先要提一下 进程、线程、协程 的区别和联系
2.1.2.1.1 进程 VS 线程
众所周知,进程是资源分配的基本单位,线程是 CPU 任务调度的基本单位,协程是轻量化的用户态线程。这句话怎么理解呢?
很多人都知道,Linux 中的进程和线程都通过 task_struct 来表示(因为其过于庞大复杂,这里不列出),但是很多人不清楚的是,线程专门对应了一个结构体 thread_struct
1 | |
从这里可以窥见线程和进程的一大区别了:需要保存的状态很少。对于 CPU 来说,其基本上只关心几个寄存器的值,所以在 thread_struct 中也主要对应这几个寄存器的状态。
更加精确的表达是:
线程是CPU执行与调度最基本的单位,每一个线程创建之初都是内核线程;创建之后如果与具体的进程上下文绑定,那线程就成了用户线程;如果此线程是进程的第一个线程,那么称之为进程的主线程;其实,在CPU执行和调度中并没有本质上的区别。
在用户角度,执行一个个程序就是创建一个个进程的主线程。当主线程创建时,同时创建用户空间,打开输入输出资源,载入依赖库等。主线程创建好后开始运行,进程也就同时存在了,这时程序可以根据需要创建用户线程,用户线程创建好后,共享主线程的用户空间,文件资源,依赖库等,用户线程退出后,主线程不会退出,进程也不会退出。当主线程退出时,内核开始关闭打开的文件,释放相关资源,主线程退出后进程也就退出了。这时,即使用户线程只执行到一半也无济于事了。
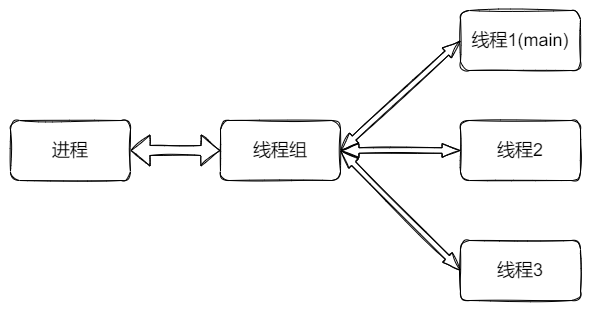
进程和线程之间是一对多的关系,这又是如何抽象出来的呢?答案在于 task_struct->thread_group。
一个进程下的所有线程会保存在 thread_groups/thread_head 链表中,并且可以通过 for_each_thread 来进行遍历
1 | |
也就是说,其实进程和线程之间存在一个抽象层(thread group),对应下面的结构
2.1.2.1.2 线程 VS 协程
线程模型存在一个很大的问题:切换开销太大(需要经过系统调用的上下文切换)。虽然相较于进程切换已经好了很多,但仍然有很大的代价。同时,线程同样使用 task_struct 这个结构体来表示,占用的内存也不可小觑。因此,人们就想要在用户空间抽象出对线程进一步细化,让不同任务的切换代价尽可能小,从而在 IO 密集型任务中提高效率。
为此,协程应运而生。
协程与内核线程是多对一的关系,也具有上下文,不过这个结构非常简单,只有几个必要的寄存器(sp,rip),这样就可以在线程上轻松自如地切换,而不用付出系统调用等开销。
2.1.2.2 Golang scheduler
既然是在用户空间对于协程进行管理,自然也少不了调度器,Golang 调度器也是历经多次改动,才成了如今高效的代名词。
下面从其发展过程中慢慢领会设计之美
2.1.2.2.1 多线程调度器
最早的多线程调度器可以描述为 G-M,其中 G 是 goroutine,M 是 kernel thread。
在多线程调度器中,每一个内核线程相当于 worker,每一个 goroutine 相当于轻量级 task,内核线程负责从 goroutine 队列中取出任务并执行,但是这样存在很严重的问题:
- 调度器和锁是全局资源,资源竞争严重
- 线程之间的 goroutine 传递带来的延迟(局部性很差)很严重
- 系统调用(线程阻塞与取消阻塞操作)非常频繁
2.1.2.2.2 任务窃取调度器
在多线程调度器的基础上,来自 Google 的工程师提出了两点改进:
- 引入中间层 P,用于抽象和管理资源
- 引入多级队列,在 P 的基础上实现任务窃取
这就是沿用至今的 G-M-P 模型。
P 它包含了运行 goroutine 的资源,如果线程想运行 goroutine,必须先获取 P,P 中还包含了可运行的 G 队列。
第二个改进点的思想主要是减少 goroutine 这个关键资源的抢占:每一个 P 管理着局部 goroutine 队列,同时还存在着全局队列,属于 P 自己的 goroutine 先用着,出队入队都不需要加锁,效率最高,再不行就去全局队列取 gorutine,效率稍低,再不行就去别的 P 任务队列中窃取,分摊压力。
2.1.2.2.3 GMP 模型
G
Goroutine 是 Go 语言调度器中待执行的任务,是一种更加细粒度的带哦度单位,使用 runtime.g 来表示
1 | |
上述字段中,需要展开的是 gobuf 结构
1 | |
关键字段的含义:
- sp:栈指针
- pc:程序计数器
- g:持有 runtime.gobuf 的 Goroutine
- ret:系统调用的返回值
这些字段是用于保存 goroutine 的执行状态,也就是 goroutine 的上下文,可以看出,确实非常轻量。
M
Go 语言并发模型中的 M 是操作系统线程。调度器最多可以创建 10000 个线程,但是其中大多数的线程都不会执行用户代码(可能陷入系统调用),最多只会有 GOMAXPROCS 个活跃线程能够正常运行。
在默认情况下,运行时会将 GOMAXPROCS 设置成当前机器的核数,我们也可以在程序中使用 runtime.GOMAXPROCS 来改变最大的活跃线程数
M 对应的结构体如下所示
1 | |
其中 g0 是持有调度栈的 goroutine,curg 是在当前线程上运行的用户 goroutine,这两者是线程运行唯一需要关心的。
P
调度器中的 processor P 是线程和 goroutine 的中间层,它能提供线程需要的上下文环境,也会负责调度线程上的等待队列,通过 P 的调度,每一个内核线程都能够执行多个 goroutine,它能在 goroutine 进行一些 I/O 操作时及时让出计算资源,提高线程的利用率
runtime.p 是处理器的运行时表示
1 | |
m 维护着线程与处理器之间的关系,而 runqhead、runqtail 和 runq 三个字段表示处理器持有的运行队列,status 字段会是以下五种中的一种:
- _Pidle :处理器没有运行用户代码或者调度器,被空闲队列或者改变其状态的结构持有,运行队列为空
- _Prunning :被线程 M 持有,并且正在执行用户代码或者调度器
- _Psyscall :没有执行用户代码,当前线程陷入系统调用
- _Pgcstop :被线程 M 持有,当前处理器由于垃圾回收被停止
- _Pdead :当前处理器已经不被使用
2.1.2.2.4 GMP 细节
- P 和 M 的创建时机?
P 创建的时机:确定了 P 的最大数量之后,Golang 运行时初始化时会创建相应数量的 P
M 创建的时机:当没有足够的 M 去和 P 关联
- GMP 执行流
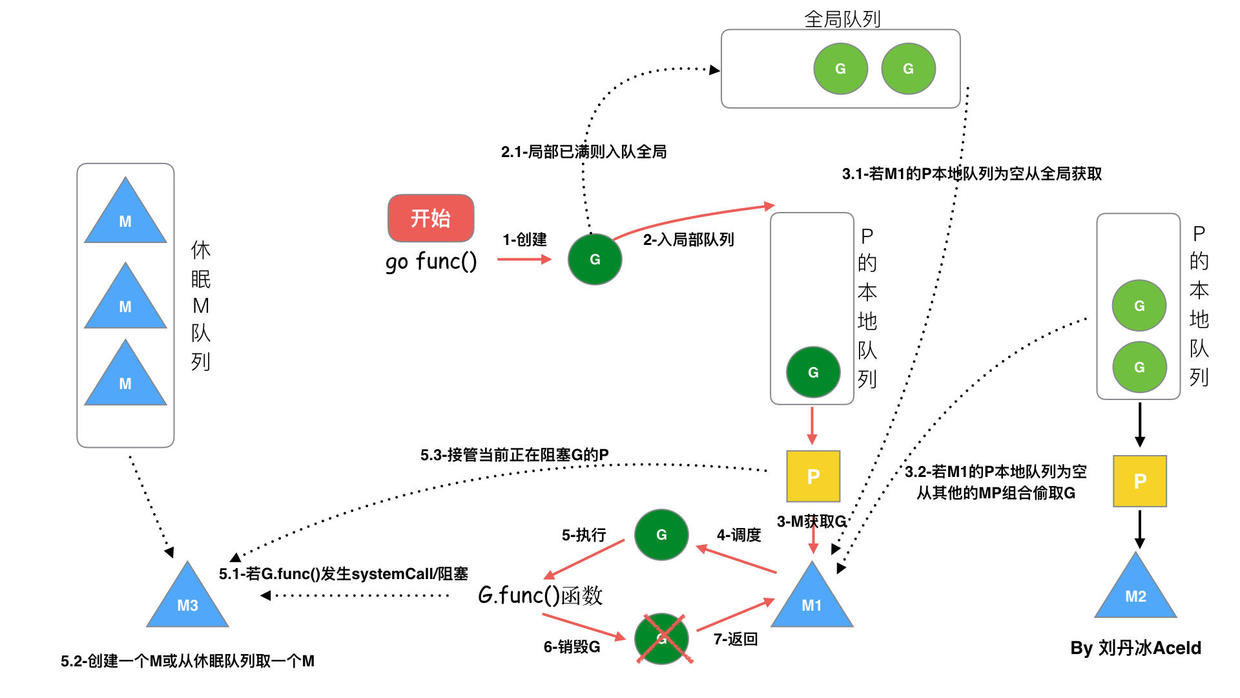
调用 go func () 创建一个 goroutine;
新创建的 G 优先保存在 P 的本地队列中,如果 P 的本地队列已经满了就会保存在全局的队列中;
M 需要在 P 的本地队列弹出一个可执行的 G,如果 P 的本地队列为空,则先会去全局队列中获取 G,如果全局队列也为空则去其他 P 中偷取 G 放到自己的 P 中
G 将相关参数传输给 M,为 M 执行 G 做准备
当 M 执行某一个 G 时候如果发生了系统调用并且导致 M 阻塞,如果当前 P 队列中有一些 G,runtime 会将线程 M 和 P 分离,然后再获取空闲的线程或创建一个新的内核级的线程来服务于这个 P,阻塞调用完成后 G 被销毁将值返回;
销毁 G,将执行结果返回
当 M 系统调用结束时候,这个 M 会尝试获取一个空闲的 P 执行,如果获取不到 P,那么这个线程 M 变成休眠状态, 加入到空闲线程中。
GMP 相较于 GM 的优化点
- 本地队列带来锁竞争的减少
- Work Stealing 算法
- 调用阻塞的系统调用时,会 detach M( M 释放绑定的 P),提高了资源利用率
2.2 字节跳动-基础架构-Rust 框架组
2.2.1 tower 中间件模型
最主要的一点是,采用了洋葱圈模型,之前的系列博客中已经详细说明其实现原理以及设计思路。
2.2.2 rpc 框架的序列化和反序列化
2.2.2.1 protobuf 编解码
带着 protobuf 体积小,编解码快的优点,来探究一下其深层的原理
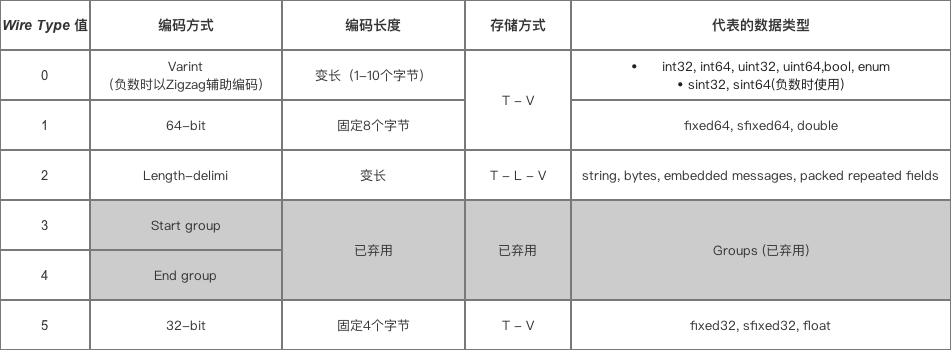
- varint 和 zigzag 的编码方式:varint 是一种变长编码方式,对于小整数,可以节约相当多的空间,而 zigzag 编码则是通过将有符号整数映射为无符号整数,解决 varint 对于负数编码效率低的问题。
- 隔断冗余信息的剔除:protobuf 首先将消息里每一个字段编码之后,再通过 key + length + data (TLV) 的方式存储数据(length 可选),减少了分隔符的使用,存储非常紧凑,空间利用率高
Xml 这种需要文档结构解析的传输方式,效率低下自不必多言,Json 虽然简单直观,但是不论是编解码还是压缩,和 protobuf 相比都不尽如人意。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!
