redis data structure
1. redis 底层数据结构
Redis 有 5 种基础数据结构,它们分别是:string(字符串)、list(列表)、hash(字典)、set(集合) 和 zset(有序集合)。这 5 种是 Redis 相关知识中最基础、最重要的部分,下面我们结合源码以及一些实践来给大家分别讲解一下。
1.1 string
众所周知,C语言中的字符串每次求长度,都需要调用 strlen 遍历,非常耗时,因此 redis 舍弃了 C 中的简单表示,转而使用动态字符串来存储。
1 | |
其中,sds 全称为 simple dynamic string,即 长度 + 动态分配的字符串指针,注意到这里的 buf 是柔性数组,利用到了 C 语言的一些语言特性,在 sds 结构体后面额外分配一块内存,就可以用于存放真正的数据
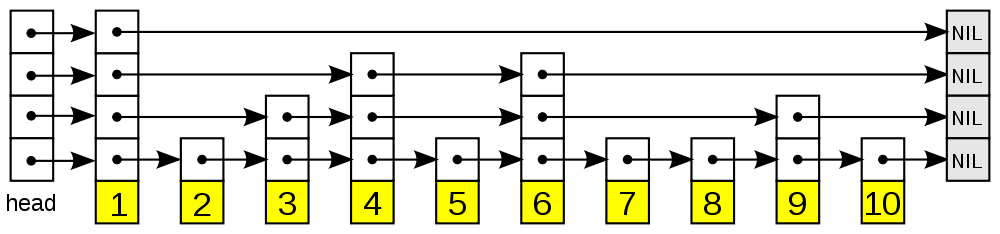
1.2 List
Redis 的列表即为双向链表,因此就具备了链表插入删除快,索引定位慢的特点。而相信大家对链表也不陌生了,这里不必多言。
1.3 Hash
Redis 作为 K,V 数据库,自然少不了高效的字典,但其实,这种字典和其它语言中默认的 HashMap 也并无太大差别,都是通过 数组+链表 解决哈希冲突。
1 | |
可以看到,dict 内部保存了两个 dict_table,这就不得不提 Redis Hash 的一大优点:rehash。
大字典的扩容是比较耗时间的,需要重新申请新的数组,然后将旧字典所有链表中的元素重新挂接到新的数组下面,这是一个 O(n) 级别的操作,作为单线程的 Redis 很难承受这样耗时的过程,所以 Redis 使用 渐进式 rehash 小步搬迁。
渐进式 rehash 会同时保留新旧两个 hash 结构,查询时也会同时查询两个 hash 结构,然后在后续的定时任务以及 hash 操作指令中,循序渐进的把旧字典的内容迁移到新字典中。
1.4 Set
相当于很多语言中的 HashSet,内部通过键值对保存,而该字典中的每一个 value 都为 NULL。
1.5 Zset
这是 Redis 最有特色的数据结构了,底层代用 skiplist 实现。
跳跃表以有序的方式在层次化的链表中保存元素, 效率和平衡树媲美 —— 查找、删除、添加等操作都可以在 O(logn) 时间下完成, 并且比起平衡树来说, 跳跃表的实现要简单直观得多
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!
